Che tradotto e sintetizzato dai nostri esperti potrebbe essere definito così:
“il GDPR è più orientato alla protezione dei dati che alla protezione dell’utente e delega direttamente alle aziende la possibilità di valutare l’entità del rischio aumentando la difficoltà dell’utente nelle evenuali contestazioni future. La reale efficacia di un regolamento del genere potrà essere davvero testata solo quando ci si troverà di fronte a casi concreti di violazione da parte di qualcuno (le stesse aziende) e alle successive contestazioni e richieste di tutela espresse dai singoli utenti. Solo in sede dibattimentale e solo al termine dei vari gradi di giudizio, si potrà valutare se questo nuovo regolamento sia più o meno efficace e in favore di chi “.Â
Insomma di sicuro aumenta il livello della protezione o meglio delle misure e della responsabilità che le aziende che “trattano” i nostri dati dovranno assumersi dal 25 maggio prossimo, e aumentano sicuramente le azioni che ogni azienda che assume i dati di utenti che transitano sul proprio sito a vario titolo (tutte diremmo per semplificare) dovrà farsi carico di mettere in atto per proteggere e tutelare tali dati. Probabilmente se anche negli Stati Uniti ci fosse stato un regolamento come questo non ci sarebbe stato nessuno scandalo “Cambridge analityca”; però – come sempre c’è un però, anzi forse ce ne sono alcuni - da qui nasce lo studio e la successiva riflessione del nostro Marco Dal Pozzo che si spinge un pochino più in là per riportarci al succo della questione e quindi lasciamo la tastiera con piacere a lui e buona lettura !
” qualsiasi informazione riguardante una persona fisica identificata o identificabile («interessato»); si considera identificabile la persona fisica che può essere identificata, direttamente o indirettamente, con particolare riferimento a un identificativo come il nome, un numero di identificazione, dati relativi all’ubicazione, un identificativo online o a uno o più elementi caratteristici della sua identità fisica, fisiologica, genetica, psichica, economica, culturale o sociale “
Alessandro Curioni, in un trattato molto interessante su questo regolamento, ” La protezione dei dati ” , pone l’attenzione anche sulla definizione appena richiamata evidenziandone un vizio: non si può – possiamo riassumere così la sue osservazioni su questo specifico aspetto – definire un dato come informazione.
L’informazione personale, esemplifica Curioni, è ciò che spiega la personalità e le convinzioni di una persona; la conoscenza personale è ciò che permette di dare un giudizio sulla persona e che quindi permette di influenzarla.
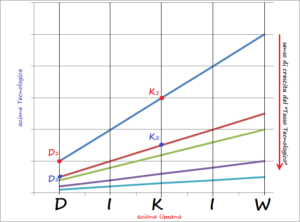
Il concetto dell’appiattimento è ancora più forte se lo schema WIKiD viene portato su un diagramma. L’artificio grafico ci dice con maggiore chiarezza che, all’aumentare del tasso tecnologico – cioè con l’imporsi di meccanismi di Intelligenza Artificiale – è molto più breve il percorso che separa il “dato†dall’â€informazione†e poi dalla “conoscenza†(nella figura il percorso sulla retta blu dal punto D1 al punto K1 è maggiore del percorso sulla retta arancio dal punto D2 a quello K2): ciò che prima era quasi interamente a carico dell’uomo (lo scienziato, il giornalista, l’artista, per dire dei lavori intellettuali di ri-elaborazione di materiali grezzi verso livelli di conoscenza dei materiali stessi), l’evoluzione tecnologica ora delega alle macchine. Si potrebbe quindi dedurre che il lavoro dell’uomo diventa sempre più quello di costruzione dell’intelligenza artificiale (che è l’infrastruttura su cui poggia il nuovo scenario in cui il percorso si compie) a svantaggio di quello di ri-elaborazione degli elementi contemplati dallo schema.
Volendo spingerci un po’ oltre, quindi, quello che andrebbe davvero fatto da un punto di vista legislativo, non è solo normare la protezione dei dati, ma garantire trasparenza su come essi vengono trattati. Il tema è, quindi, ancora una volta, la trasparenza degli algoritmi.