Disobbedienti si diventa
 Bentrovati per la lettura della seconda parte della nostra scheda dedicata al saggio di Nicola Zamperini edito per Castelvecchi che si intitola “Manuale di disobbedienza digitale”. Prima di proseguire nella lettura del saggio e nella conseguente estrazione di quei passaggi che abbiamo giudicato particolarmente interessanti, vorremmo dedicare l’apertura di questo post alla parte conclusiva del volume. Le 100 regole di disobbedienza che l’autore inserisce in coda al volume e che fra il serio e il faceto costituiscono il pretesto, ma anche il senso più vero e profondo dell’opera. L’ennagolo come lo definisce Zamperini, un elenco lungo ma nemmeno troppo di suggerimenti,  perchè, come dice lui stesso citando il romanzo Il disertore di Jean Giono: “disertori non ci si improvvisa e di un buon fuggiasco occorrerà ricordare la cura con cui ha cancellato la sua pista”. Per continuare nel nostro gioco del mettere in evidenza e segnalare, abbiamo provato ad estrarre 10 di queste cento regolette, quelle che a nostro insindacabile avviso sono le più urgenti e forse anche le più facilmente attuabili o magari solo le più poeticamente suggestive, quelle che, sempre a nostro avviso, restituiscono meglio a ciascuno di noi un pezzettino della nostra umanità de-algoritmicizzata (perdonate l’ardire per aver appena scritto in piena coscienza una parola che non esiste nei vocabolari della lingua italiana). Le scriveremo rigorosamente in ordine sparso e senza alcun riferimento numerico rispetto al vero e unico “ennagolo” di Zamperini, a Voi capire previo lettura dell’elenco originale dove le abbiamo prese e con quale intento l’autore le aveva inserite proprio in quell’ordine.
Bentrovati per la lettura della seconda parte della nostra scheda dedicata al saggio di Nicola Zamperini edito per Castelvecchi che si intitola “Manuale di disobbedienza digitale”. Prima di proseguire nella lettura del saggio e nella conseguente estrazione di quei passaggi che abbiamo giudicato particolarmente interessanti, vorremmo dedicare l’apertura di questo post alla parte conclusiva del volume. Le 100 regole di disobbedienza che l’autore inserisce in coda al volume e che fra il serio e il faceto costituiscono il pretesto, ma anche il senso più vero e profondo dell’opera. L’ennagolo come lo definisce Zamperini, un elenco lungo ma nemmeno troppo di suggerimenti,  perchè, come dice lui stesso citando il romanzo Il disertore di Jean Giono: “disertori non ci si improvvisa e di un buon fuggiasco occorrerà ricordare la cura con cui ha cancellato la sua pista”. Per continuare nel nostro gioco del mettere in evidenza e segnalare, abbiamo provato ad estrarre 10 di queste cento regolette, quelle che a nostro insindacabile avviso sono le più urgenti e forse anche le più facilmente attuabili o magari solo le più poeticamente suggestive, quelle che, sempre a nostro avviso, restituiscono meglio a ciascuno di noi un pezzettino della nostra umanità de-algoritmicizzata (perdonate l’ardire per aver appena scritto in piena coscienza una parola che non esiste nei vocabolari della lingua italiana). Le scriveremo rigorosamente in ordine sparso e senza alcun riferimento numerico rispetto al vero e unico “ennagolo” di Zamperini, a Voi capire previo lettura dell’elenco originale dove le abbiamo prese e con quale intento l’autore le aveva inserite proprio in quell’ordine.
Se siete una coppia non parlatevi mai sui social network. Mai
Quando vi iscrivete ad un social network date informazioni false
Comprate una scatola, stampate 20 foto l’anno e sopra scriveteci il nome dei vostri figli: li aiuterà alla vostra morte a saperne di più di voi (e non di meno)
Non invitate amici da un’applicazione a un’altra, da Instagram a Facebook. Soprattutto non lo fate in blocco
Se qualcosa vi indigna manifestate. Per strada
Navigate liberamente per il web fuori da Google e da Facebook rimbalzando di sito in sito
Quando scrivete uno status pensate sempre che possono vederlo tutti. Letteralmente tutti
Non usate Maps, almeno in città , correte con entusiasmo il rischio di perdervi
Disattivate tutte le funzioni di geolocalizzazione di tutte le App che utilizzate sullo smartphone
Non dormite con lo smartphone sul comodino e non utilizzatelo come torcia per andare in bagno (è una scusa per controllare le notifiche)
Torniamo dunque ora ad occuparci degli specifici contenuti del libro che stiamo esaminando e ricominciamo a estrarre qualcuno dei passaggi a nostro avviso più significativi del volume cominciando dal capitolo davvero illuminante del saggio di Nicola Zamperini dove l’autore ci racconta l’origine dei famigerati captcha e dei loro figli più o meno legittimi i re-captcha.
La grande rimozione. Aziende Spietate
“Captcha è un acronimo: Completely Automated  Public Turing test to tell Computers and Humans Apart”, ovvero un test di Turing pubblico e completamente automatico per distinguere computer e umani. Nel cosiddetto re-Captcha le lettere che dobbiamo interpretare non sono più casuali. (…) Se il primo modello di questo software serviva a rassicurare sul fatto che un uomo è un uomo e basta, il re-Captcha ha un altro fine. I nuovi numeri o le lettere che compaiono quando vogliamo iscriverci a una newsletter, emergono come il frutto della scannerizzazione di milioni di pagine di libri antichi e manoscritti. (…) I cosiddetti OCR (software di riconoscimento ottico di caratteri per la trasformazione in documenti digitali) non erano così bravi da interpretare e tradurre tutte le lettere di un testo vecchio, figuriamoci quelle di un libro antico. Serve l’essere umano. (…) Immaginate i costi enormi per un programma di acquisizione e conversione, destinato a milioni e milioni di volumi, affidato alle cure di uomini in carne e ossa. (…) I ricercatori della Carnegie Mellon University di Pittsburgh hanno quindi escogitato un sistema che utilizza il caro e vecchio Captcha per risolvere il problema e abbattere radicalmente i costi. Anzi, per non spendere proprio nulla! Hanno scannerizzato i volumi antichi e per l’analisi del testo più difficile e ostico degli OCR si sono affidati all’uomo, ma non a un vasto gruppo di ricercatori, decodificatori con nome, cognome e un contratto di impiego. No. Quel lavoro l’abbiamo fatto noi. (…) Siamo tutti noi che gratuitamente abbiamo interpretato e regalato, e che continuiamo a regalare, il frutto della nostra intelligenza in cambio di un servizio – anch’esso apparentemente gratuito, certo – come la mail. E abbiamo risolto questo gigantesco problema con successo: il tasso di accuratezza nell’interpretazione arriva al 99%. Ecco perchè il sistema reCaptcha è stato poi acquistato da Google. L’azienda ne ha fatto il cuore del progetto di digitalizzazione di tutti i libri delle più importanti biblioteche del pianeta. Centinaia di milioni di esseri umani nel mondo hanno inconsapevolmente aiutato e lavorato per Google, collaborando a correggere le scansioni dei libri di Google Books. Non c’è nulla di male a mettere sul piatto uno scambio alla pari e chiedere agli utenti: Vuoi Gmail gratis? Allora aiutami a tradurre questo testo che non sono capace. Oppure dire: Aiutami ad aiutarti, non ho alcuna intenzione di spendere tanti soldi,  però voglio darti la mail gratis. La maggior parte di noi avrebbe accettato senza fiatare. Però Google non l’ha mai chiesto, ha sempre dimenticato di sottolineare l’esistenza e il fine dello scambio“.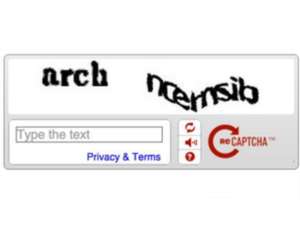
“In buona sostanza abbiamo assimilato con facilità e velocità il concetto che Google somigli a una specie di università popolata da giovani menti brillanti che dedicano il 20% del tempo lavorativo a studiare tecnologie che liberano l’essere umano e lo facciano vivere meglio, i creativi smart, idranti di nuove idee, nelle parole di Schmidt e che qualche anno prima altri avevano definito analisti simbolici. (…) Google ha scelto che l’università rappresentasse la sua identità : non una multinazionale, ma un’università di cervelloni specializzati in infiniti settori. Non un quartier generale ma un campus. Non dirigenti ma fellow. Google lavora per la collettività . Si dedica all’interesse generale. Google ha a cuore il destino di noi tutti. Come le Nazioni Unite non parteggia, non tifa, pensa alla pace nel mondo e alla crescita degli individui. Facebook non è differente. Un’istituzione benevola. Ecco la chiave con cui si autorappresenta la Silicon Valley nel suo complesso. Se si pensa alla General Motors, alla Coca-Cola si pensa ad aziende che vendono macchine comode e bibite gassate per farci stare meglio, per raggiungere uno status, rilassarci, muoverci: vendono beni in cambio di soldi. Qui la seconda metà dell’equazione – i cambio di soldi – è svanita. Ricapitoliamo: grazie all’identificazione tra le aziende della Silicon Valley e le istituzioni accademiche, a un certo punto abbiamo confuso la natura di queste ultime con la loro funzione e il loro modo di autorappresentarsi. Abbiamo dimenticato che sono aziende spietate, come quasi tutte le aziende, e le abbiamo scambiate per istituzioni benefiche“. Â
Super-aziende o meta-nazioni digitali?
“Abbiamo assistito alla nascita di un nuovo modello di aziende. Aziende che operano in tutti i paesi del mondo e che hanno costruito una cultura, rappresentato e raccontato una storia e adesso sono sedute sul trono dei nostri comportamenti quotidiani. (…) Per molte persone navigare nel web significa essere connessi a Facebook oppure utilizzare Google e le sue infinite applicazioni. Una delle prime caratteristiche delle techno-corporation è che non si limitano a fare un unico mestiere. Ne fanno sempre quattro-cinque, in cui diventano monopoliste, e poi dal mestiere apparentemente principale, che in apparenza è gratuito, lasciano scaturire business paralleli. E sul singolo mestiere, compito e funzione traggono ricavi ed effetti primari, secondari e terziari che si sommano. Facebook di primo mestiere fa il social network gratuito per il pubblico, poi vende pubblicità alle aziende di tutto il pianeta, spazi video alle stesse aziende, gestisce una specie di televisione planetaria, regala il più diffuso sistema di messaggistica istantanea del mondo, gestisce il più importante data base di immagini realizzato dagli utenti del pianeta (Instagram), che per inciso è anche un altro social network, produce device di realtà virtuale comme Oculus VR, ed è appena entrata nell’e-Commerce. Google di primo mestiere fa il motore di ricerca gratuito per il pubblico, poi vende pubblicità alle aziende di tutto il mondo, sia testuale che video, produce telefoni con il loro sistema operativo, offre servizi di traduzione istantanea, produce macchine senza pilota, produce robot che sono assistenti personali. (…) Simili a qualunque media, le techno-corporation intercettano l’immaginario degli uomini. Come in passato, e in parte, faceva la televisione ad esempio,costruiscono contenitori per racconti e all’interno di questi contenitori vendono pubblicità e pensiero. Alcune novità , però, rompono rispetto ai media tradizionali e scatenano una potenza mai vista prima: in primo luogo la portabilità dei dispositivi e dunque l’onnipresenza del loro contatto e della loro funzione. Ubiquità connessa alla multimedialità e all’interattività e quindi alla condivisione e alla partecipazione attiva – con tutti i sensi – rispetto al flusso di cose dette, scritte, lette, viste, ascoltate. Secondo: per le aziende normali tra i fattori più importanti ci sono reputazione e scelta d’acquisto dei clienti. Per le techno-corporation la scelta più importante è che il cliente viva nel suo spazio, indipendentemente dal fatto che acquisti o meno, e questo è alla base della loro reputazione. (…) Google compone il mio profilo grazie alla mia storia di ricerca, alle mie mail, ai miei percorsi su Google Maps, alla mia posizione geografica e via dicendo. E se a ciascuna di queste funzioni è connessa una pubblicità oltre all’identikit dell’utente, c’è qualcuno che paga per il suo click “.
“In Italia 30 milioni di persone su 60 milioni, la metà del totale, anziani, neonati e analfabeti compresi, si raccontano senza filtri su Facebook. Spiega Christian Rudder, presidente di OkCupid, in Dataclisma: Tutte queste società sono per prima cosa delle fenomenali imprese economiche, ma in seconda battuta sono anche degli strumenti demografici di portata, accuratezza e importanza senza precedenti. Come se niente fosse, oggi i dati digitali ci possono mostrare come litighiamo, come amiamo, come invecchiamo, chi siamo e come stiamo cambiando. (…) Oggi il censimento è immediato e lo realizzano soggetti privati che conoscono, in tempo reale, molte più cose di quante ne conosca l’Istat o lo United States Census Bureau. Un’azienda maneggia la demografia, non per sapere e fornire alle istituzioni elementi utili alle decisioni prese nell’interesse della comunità , ma per il proprio profitto “.
“In molti sensi Facebook è più simile a un governo che a una azienda tradizionale, abbiamo una grande comunità di persone, e più di ogni altra azienda, dobbiamo ragionare in termini di policy. Ragionano in termini politici, e questo dovrebbero fare le istituzioni quando si confrontano con le techno-corporation. (…) Per tutte queste ragioni crediamo che annoverare le aziende della Silicon Valley nella categoria imprese non sia più sufficiente. Non spiega e non definisce. Vanno analizzate con lenti multifocali che consentano la lettura di piani sovrapposti. (…) Leggere Facebook da tecnologi è riduttivo oltre che sciocco. E così leggerla come media company. Allo stesso modo interpretare la cultura aziendale di Google con i soli occhi della politica è altrettanto fuorviante. Sono meta-nazioni digitali senza territorio fisico, con cittadini, regole, territori e vessilli, interessi nazionali e dunque anche commerciali, politiche di sviluppo, rappresentanti non eletti. Sono moderni Leviatani e si rapportano con i cittadini-utenti-clienti comportandosi come sovrani, titolari di potere e poteri che emanano dalle proprie formule tecnologiche; hanno stabilito unilateralmente proprie norme di comportamento pratiche e morali (non si pubblica un capezzolo su Facebook!), sia per l’esistenza in vita dei sudditi che per il post mortem; all’interno di questo spazio sono naturalmente legibus soluti e nessuno vi è più alto in grado che possa costringerli a fare qualcosa, salvo quando essi decidano di aprirsi alla collaborazione, ad esempio con le forze di polizia; hanno rapporti con altre aziende di ogni dimensione, si scontrano e si confrontano con istituzioni nazionali e sovranazionali, possiedono una lingua universale, l’inglese, ma si uniformano alla lingua del luogo; dispongono di una cultura e di una storia; custodiscono i propri interna corporis acta – gli algoritmi – norme segrete eppure venerate come carte fondamentali, brevetti e invenzioni, strumenti del loro dominio; estendono il proprio regno su quasi ogni terra emersa del pianeta; esibiscono missioni aziendali globali, illimitate, che rasentano i confini di un programma politico; dispongono di università e centri di ricerca e formazione tra i più avanzati sul pianeta; stimolano lo studio della propria attività ; attivano politiche di sicurezza per difendersi da ogni nemico digitale interno od esterno. (…) Anche il loro modello di business, fin qui basato sulla pubblicità , potrebbe essere inteso come una specie di prelievo fiscale sulle aziende, che in questo modo entrano in contatto con i cittadini utenti ” .
Le impostazioni predefinite e i giardini protetti
” Google è partita cercando di misurare quello che le persone pensano ed è finito per diventare quello che le persone pensano. Facebook è partito cercando di disegnare la mappa del tracciato sociale ed è diventato il tracciato sociale. La vita fuori dagli spazi regolati dagli algoritmi è ovviamente differente. E la colossale opera di filtraggio che essi realizzano è un modo di censurare tutto ciò che di scomodo, controverso, politicamente scorretto esiste nel pianeta. Il grande alibi è il deep web o dark web, quella porzione più o meno segreta, illecita, nascosta e profonda di internet, in cui prospererebbero ogni genere di traffici illeciti e di attività pericolose per il pianeta. In realtà navigare nel web profondo è come tornare a prima dell’internet per idioti. Prima della bolla speculativa, del web 2.0, dei markettari, dei social. Qui non hai la pappa pronta con motori che ti dicono cosa cercare.
Il libro di Nicola Zamperini è davvero una bussola, un testo fondamentale per orientarsi nel difficile, oseremo dire, quasi impossibile, percorso di acculturamento digitale della nostra società globale. Quel processo oramai irrinunciabile che dovrebbe, a nostro giudizio, stare alla base della cultura sociale quotidiana di tutti noi, in tutti i Paesi del mondo, e per tutti i Governi dei Paesi del mondo. Governi che prima di trattare e mettersi a discutere e a negoziare la propria sovranità con i Ceo delle techno-corporation, dovrebbero mettere in grado i propri cittadini di sapersi orientare coscientemente e con un buon grado di conoscenza dentro ai meandri della rete, completamente o quasi, colonizzati dalle OTT e trasformati – come dice molto bene lo stesso Zamperini – in meta-nazioni digitali.